
Obsah
- 1 Jak porovnat poměr pohlaví ve dvou skupinách r
- 2 Vizualizace výsledků v R: první kroky
- 3 Srovnání prostředků v R
- 4 Co přesně je tady špatně?
- 5 Analýza rozptylu a srovnání několika skupin
- 6 Proč R?
- 7 Pokud začínáte s analýzou hlavních dat:
- 8 Pokud již máte zkušenosti s analýzou dat:
- 9 Online kurz R v ruštině: tři týdny analýzy dat
- 10 Program kurzu
Jak porovnat poměr pohlaví ve dvou skupinách r
Vizualizace výsledků je nedílnou součástí výzkumu, například publikování článku nebo podání zprávy atd. Správné zobrazení získaných rozdílů přitom není jen záležitostí estetickou (i když efektní vizualizace samozřejmě přinejmenším upoutá pozornost posluchačů!), ale také čistě statistickou. Vždy se mi líbil přístup, že graf by měl obsahovat ucelenou zprávu o provedené práci: jaké skupiny byly porovnávány, na které proměnné, zda byly nalezeny statisticky významné rozdíly atd.
Vizualizace výsledků v R: první kroky
V jednom z předchozích příspěvků jsme již psali o ústředním pojmu ve statistice – p-hladině významnosti. A zatímco ve vědecké komunitě pokračují debaty o interpretaci p-hodnoty, značná část výzkumu se provádí pomocí p-hodnoty, aby se zjistila významnost rozdílů získaných ve studii. Dnes si povíme o nejkreativnější fázi zpracování dat – jak vizualizovat výrazné rozdíly.
Vizualizace výsledků je nedílnou součástí výzkumu, například publikování článku nebo podání zprávy atd. Správné zobrazení získaných rozdílů přitom není jen záležitostí estetickou (i když efektní vizualizace samozřejmě přinejmenším upoutá pozornost posluchačů!), ale také čistě statistickou. Vždy se mi líbil přístup, že graf by měl obsahovat ucelenou zprávu o provedené práci: jaké skupiny byly porovnávány, na které proměnné, zda byly nalezeny statisticky významné rozdíly atd.
Srovnání prostředků v R
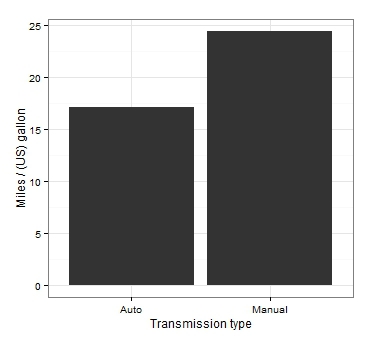
Podívejme se na jeden z nejpopulárnějších typů grafů – porovnávání průměrů – a zjistěte, jak je lze sestavit v R pomocí pouhých několika řádků kódu. Použijme data mtcars zabudovaná do R, která poskytují informace o různých technických vlastnostech 32 vozů. Porovnejme průměrné hodnoty spotřeby paliva u vozů s automatickou a manuální převodovkou.
mtcars$am
výsledky t-testu:t = -3.7671, df = 18.332, p-hodnota = 0.001374 alternativní hypotéza: skutečný rozdíl v průměrech není roven 0 95procentní interval spolehlivosti: -11.280194 -3.209684 výběrové odhady: průměr ve skupině 0 průměr ve skupině 1 17.14737
Byly nalezeny statisticky významné rozdíly, nezbývá než si výsledek vizualizovat. Začněme s grafem šampiónů v kategorii „jak nezobrazovat srovnání průměrů“.
Co přesně je tady špatně?
I když připustíme, že průměry jsou zobrazeny ve sloupcích, hlavní nevýhodou tohoto typu grafu je nedostatek měřítek variability v našich datech. Při pohledu na takový graf není vůbec jasné, zda byly získány významné rozdíly. A jediný závěr, který můžeme vyvodit, je: pravý sloupec je výše než levý!
Vylepšeme původní verzi následovně: zobrazte průměry jako tečky a přidejte intervaly spolehlivosti:
library(ggplot2) ggplot(mtcars, aes(am, mpg))+ stat_summary(fun.data = mean_cl_boot, geom = "errorbar", width = 0.1, size = 1)+ stat_summary(fun.y = mean, geom = " bod", velikost = 6, tvar = 22, výplň = "bílá")+ theme_bw()+ xlab("Typ převodovky")+ ylab("Míle / (US) galon")
Mnohem lepší! Za prvé, nepřekrývající se intervaly spolehlivosti podporují náš závěr, že rozdíly jsou statisticky významné. Za druhé, pro pozorného pozorovatele tento graf také poskytuje další informace o podrobnostech našich dat: je snadné vidět, že interval spolehlivosti pro průměrnou spotřebu paliva ve skupině s manuálním řazením je mnohem širší. V našem případě je to vysvětleno odlišnou hodnotou směrodatné odchylky ve skupinách (tuto informaci v zásadě nelze získat pohledem na „sloupcový“ graf).
Analýza rozptylu a srovnání několika skupin
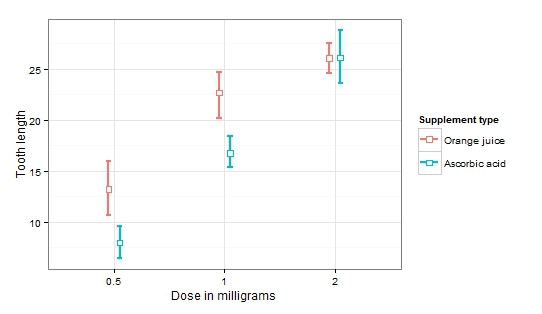
Podívejme se nyní na zajímavější možnost pomocí analýzy rozptylu a porovnání několika skupin. Využijme další data zabudovaná v R – ToothGrowth. Data nám umožňují studovat růst zubů u morčat v závislosti na dávkování vitaminu C a druhu konzumované potravy. Aplikujme analýzu rozptylu:
Výsledky analýzy:
Df Sum Sq Mean Sq F hodnota Pr(>F) dávka 1 2224.3 2224.3 133.415 < 2e-16 *** supp 1 205.3 205.3 12.317 0.000894 *** dávka:supp 1 88.9 88.9idu5.333 0.024631 56Vidíme, že jak vliv každého faktoru zvlášť, tak jejich interakce se ukázaly jako významné. To je rozhodně případ, kdy je velmi obtížné vyvozovat jakékoli závěry bez vizualizace.
ggplot(ToothGrowth, aes(faktor(dávka), délka, col = supp))+ stat_summary(fun.data = mean_cl_boot, geom = "errorbar", width = 0.1, size = 1, position = position_dodge(0.2))+ stat_summary (fun.y = mean, geom = "point", size = 3, shape = 22, fill = "white", position = position_dodge(0.2))+ theme_bw()+ xlab("Dávka v miligramech")+ ylab( "Délka zubu")+ scale_color_discrete(name = "Typ doplňku", štítky = c("Pomerančový džus", "Kyselina askorbová"))
Nyní je snadné zaznamenat nárůst průměrné délky zubu se zvyšujícím se dávkováním (významný dávkovací faktor). Navíc se zvyšujícím se dávkováním mizí vliv typu přípravku (významný faktor typu přípravku a interakce faktorů).
Vynesení intervalů spolehlivosti do grafu nám tedy umožňuje nejen posoudit, jak statisticky významné jsou získané rozdíly, ale také poskytuje příležitost získat představu o povaze variability v rámci porovnávaných skupin. Níže je rychlé připomenutí vztahu mezi vzdáleností mezi intervaly spolehlivosti a přibližnou p-hodnotou.
Proč R?
V dnešní době existuje mnoho nástrojů pro analýzu dat a vizualizaci výsledků, z nichž některé umožňují aplikovat poměrně širokou škálu statistických metod bez jakýchkoli zkušeností s programováním (například SPSS). Programovací jazyk Python je také velmi běžný pro analýzu dat.
Pokud začínáte s analýzou hlavních dat:
- R je velmi jednoduchý a intuitivní programovací jazyk. Osvojením si základů práce v R si výrazně zjednodušíte a urychlíte řešení svých problémů.
- Práce v R poskytuje cenné zkušenosti a pomáhá při učení složitějších programovacích jazyků.
- Vizualizace samozřejmě! V tomto článku jsme zkoumali pouze nejzákladnější verzi grafů, ale i ta vypadá mnohonásobně hezčí než vizualizace v programech pro analýzu dat s grafickým rozhraním.
Pokud již máte zkušenosti s analýzou dat:
- R má tisíce balíčků a knihoven, které poskytují možnost použít snad úplně jakékoli statistické metody. Speciální knihovna lme4 vám umožní implementovat regresní analýzu s náhodnými efekty v R. Například s použitím jazyka Python je to mnohem obtížnější!
- R má mnoho knihoven, které jsou psány přímo výzkumníky a vědci, aby řešily vysoce specializované problémy z různých vědeckých oblastí. Například bioconductor poskytuje nástroje pro analýzu dat v bioinformatice. Knihovna grt vám pomůže zpracovat experimentální data v oblasti výpočtových modelů v kognitivní vědě! Speciální knihovny vám pomohou zpracovat výsledky EEG, FMRI nebo studie, která zaznamenává pohyby lidského oka pomocí eye trackeru.
- Konečně vám R umožňuje rychle interaktivně řešit širokou škálu problémů.
Online kurz R v ruštině: tři týdny analýzy dat
Před nedávnem byl na platformě Stepic dokončen online kurz úvodu do statistiky, věnovaný základním metodám analýzy dat. Náš nový třítýdenní online kurz od Bioinformatického institutu seznámí studenty se základy programování v jazyce R.
V prvním týdnu se naučíme manipulovat s daty a seznámíme se se základní syntaxí jazyka. Druhý a třetí týden kurzu je věnován aplikaci základních statistických testů a vizualizaci výsledků. Kurz je v ruštině a pro každého zcela zdarma! Zaregistrujte se: Analýza dat v R
Program kurzu
- Proměnné
- Práce s datovými rámci
- Deskriptivní statistika
- Deskriptivní statistika. Grafy
- Ukládání výsledků
- Analýza nominativních dat
- Srovnání dvou skupin
- Aplikace analýzy rozptylu
- Vytváření vlastních funkcí
- Korelace a jednoduchá lineární regrese
- Vícenásobná lineární regrese
- Diagnostika modelu
- Binomická regrese
- Export výsledků analýzy z R


- Analýza dat v R
- statistika
- vizualizace dat





